

The AI Wrote the Code. I Still Had To Teach It Baseball.
Part 3 of 5: The BenchBoard Build — How I Bit Off More Than I Could Chew Building This SaaS Even With the "Best" LLMs

This is Part 3 of a five-part series about building BenchBoard, a team management and live scorekeeping app for youth baseball and softball, with the help of AI tools. Part 1 covers the big-picture lessons of building with AI. Part 2 is the technical deep dive: the race condition, the three-tables-to-one refactor, the pipeline I designed after the AI’s fix wasn’t good enough. Start there if you want the full context.
So.
November was the month BenchBoard went into production.
Not “production” in the way people on Twitter mean it. Not a landing page with a Stripe checkout and a waitlist. Real production. A deployed app on Azure, behind authentication, with a database, a real-time communication layer, and actual functionality. Coaches could create teams, add players, drag them into batting orders and defensive positions, and see everything sync across devices.
I soft-launched it. No marketing. No ads. I put it out there and let search do its thing.
And people found it. Real coaches. Not friends I’d asked to test. Not developers giving polite feedback. Coaches who were actively looking for a tool to manage their youth baseball and softball teams, who found BenchBoard through Google, signed up, and started using it. Just a dozen of them.
That’s when I got the feedback that changed everything.
“It’s a Nice Toy”

I’m paraphrasing, but that was the essence. The coaches who found BenchBoard liked the team management side. The drag-and-drop lineup builder, the roster, the field diagram. They could see the potential. A few of them told me it was the cleanest interface they’d found for organizing their team.
Then came the “but.”
“But I need data. I need to know who’s playing where and for how long. I need to track at-bats. I need pitch counts. I need to know if I’m giving my left fielder enough innings or if the same three kids are always pitching. I need this thing to help me make *decisions*, not just arrange a lineup card.”
That hit hard. Because they were right.
Without game data, BenchBoard was a pretty roster. A digital lineup card. Coaches don’t need help making a list. They need help managing a season. They need to know that Jennie has pitched 45 pitches this week and shouldn’t start again until Thursday. They need to know that the kid who’s been sitting on the bench for three innings is the same kid whose parents are starting to wonder if the coach plays favorites. They need the numbers. In youth sports, fairness isn’t optional. It’s the whole point.
And they couldn’t get those numbers from BenchBoard.
At least not yet.
The Options I Explored (And Why They Failed)

My first instinct wasn’t to build scorekeeping from scratch. That sounded insane. Surely somebody else had solved this, and I could integrate with them. As I was doing research, I noticed there are a dozen solutions out there, but they need to be robust and most of all they need to be real-time. Out of the dozens available, it boiled down to two candidates.
GameChanger was the obvious one. It’s the most widely used scorekeeping app in youth baseball and softball. If I could pull data from GameChanger into BenchBoard, I’d have instant access to pitch counts, at-bats, innings played. Everything the coaches were asking for.
One problem: GameChanger’s APIs aren’t public. There’s no integration path. You can’t programmatically access the data. It’s a walled garden. I poked around at some git repositories and noticed someone tried to scrape it and reverse-engineer their endpoints, but that’s fragile, probably against their terms of service, and not something I’d want to build a product on. That, and the fact that my two kids have their stats on there.
iScore was another option. They’ve been around longer and they do have some data export capabilities. But when I dug into it, the data fidelity wasn’t there. The connectors didn’t provide the level of detail these coaches were asking for. No play-by-play granularity. No per-player breakdowns across multiple games. It would’ve been a compromise from day one.
I looked at a few others. None of them gave me what I needed: a reliable, real-time data pipeline that could feed directly into BenchBoard’s team management layer and produce the coaching analytics these coaches were describing.
Which left the one option I’d been avoiding.
Build it myself.
Going Head-to-Head With GameChanger

Before I could commit to that, I had to answer an uncomfortable question. Why would anyone use BenchBoard’s scorekeeping when GameChanger already exists?
GameChanger is the 800-pound gorilla in this space. They have the market. They have the brand. They have the streaming feature that parents pay for. And let me be honest: their scorekeeping is solid. They track pitches, at-bats, game events. Their live stream shows real data because a scorekeeper is feeding it in real time. They do a lot of things well.
So I wasn’t sitting here thinking I could out-GameChanger GameChanger on day one. That would be delusional.
What I *was* thinking about was the gap between what GameChanger tracks and what a coach actually needs to *manage their team*.
GameChanger records the game. It tells you what happened. Who got a hit, who struck out, what the score was. But it doesn’t provide reports on *coaching decisions*. It doesn’t provide insight that the coach moved their right fielder to pitcher in the third inning and that decision led to three consecutive walks. It doesn’t advise the coach that the same three kids have been sitting on the bench for two innings while the starters play every position. It doesn’t connect lineup management to game outcomes in a way that helps a coach answer the question: “Am I managing this team fairly, and are my decisions working?”
Or from a competitive standpoint, am I making the best decision for this situation? Could the San Francisco Giants use this? Oh the dream of it all. Would it be overkill? And to do this in real-time? That’s the goal.
That question matters differently depending on the league. In a rec league, fairness is everything. Every kid is supposed to get equal playing time, and parents notice when their child sits more than others. In a competitive league, it’s about development. At least for most travel teams. Is this kid getting the right mix of positions and at-bats to grow?
Either way, the data has to connect what the coach decided to what happened on the field. Hence the “Nice toy”.
Once in awhile a bit of doubt creeps in and says “would this ruin youth sports?” I guess that depends on every coach.
GameChanger doesn’t have that connection because it doesn’t manage the team. It scores the game. Those are different products.
BenchBoard manages both. The lineup builder, the roster, the drag-and-drop defensive positions - all of that feeds directly into the scorekeeping engine. When a coach makes a substitution mid-game, BenchBoard knows it was a coaching decision, not just a lineup change. When the scorekeeping data shows that substitution led to a scoreless inning, that’s actionable intelligence. When it shows a kid has only played two innings across three games, that’s an equity flag.
That realization was what moved me from “this is daunting” to “this is necessary.” If I build the scorekeeping engine right, tightly coupled to the team management layer, I’m not just catching up to GameChanger. I’d also make the real-time APIs public and consumable by other developers. If developers want to build a scoreboard in the middle of the field with my APIs, they can. I’m building something GameChanger’s team would have to fundamentally restructure to replicate.
A Full-Blown App, Inside the App I Just Finished
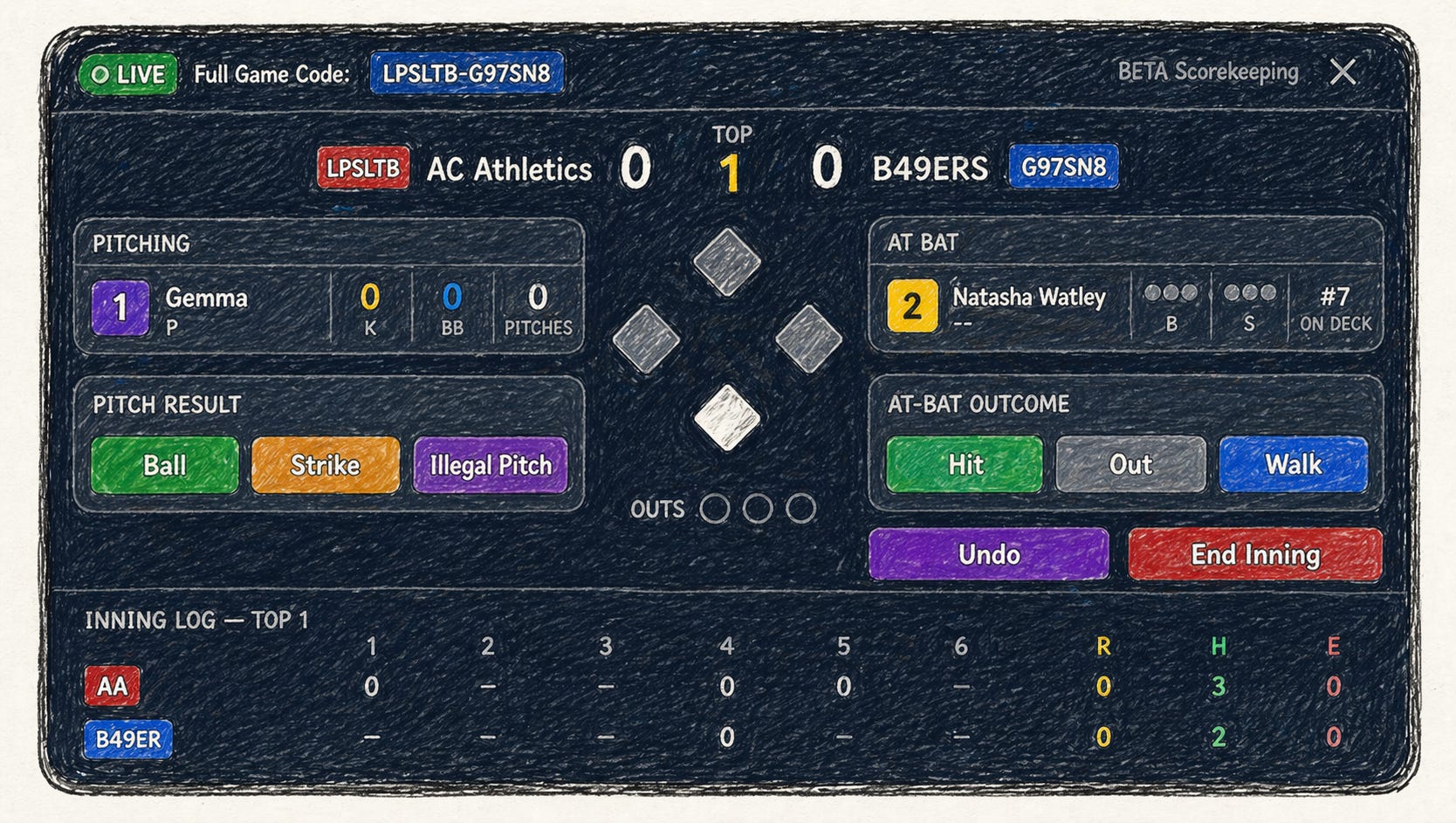
I ended Part 2 by telling you the decision to build scorekeeping terrified me. Let me walk that back a little, because it’s not quite right.
With 30+ years of building software, code doesn’t scare me. I was shaking my head. Because I knew exactly what I was looking at. Building *another* app. Not a feature. Not an add-on. A full-blown *system of record* for live game data - even with AI agents behind me doing a good chunk of the work.
And if you know anything about building systems of record, you know they have to be robust and reliable from day one. You don’t get to ship a “pretty good” scorekeeping engine and iterate. If the data is wrong, coaches make wrong decisions. If it’s unreliable, nobody trusts it. If it drops a pitch or miscounts an at-bat, you’ve lost that user forever. The irony is that’s where the code stands now and scorekeeping is in Beta. Ok for scrimmages. Not for tournaments or even Little League.
That’s a high bar for any project, let alone one you’re bolting onto an existing app that already took months to stabilize. The team management side of BenchBoard had just taught me how hard the “simple” part was. The three-table refactor. The race condition. The 36 migrations. The localStorage cross-contamination. All of that was the warm-up.
Now I was looking at scorekeeping. And I realized the coach’s feedback was mine too.
On one of my reporting pages, I have a feature called *Position Heat Maps*. Innings played at each position, rendered as a grid. The darker the cell, the more innings that player has played there.
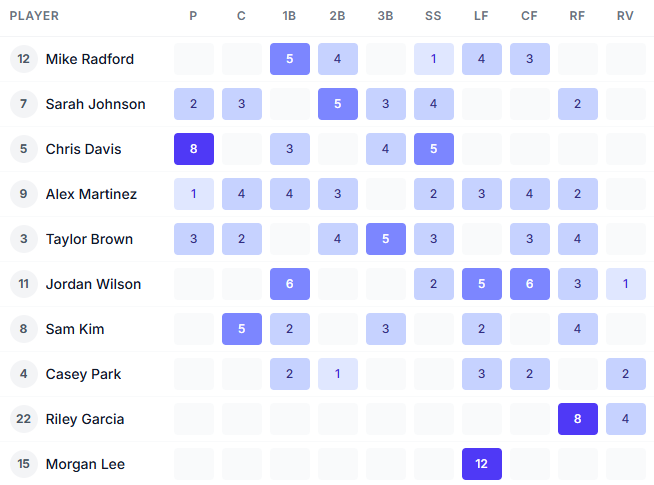
It’s how a coach spots, in two seconds, that the same three kids have been pitching all season. That kind of visibility only exists if the underlying data exists.
Now check out this…
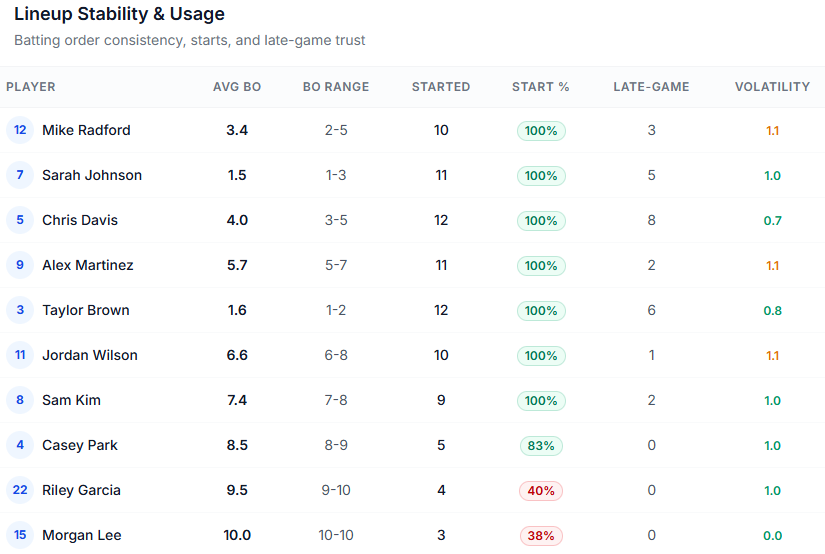
and this…
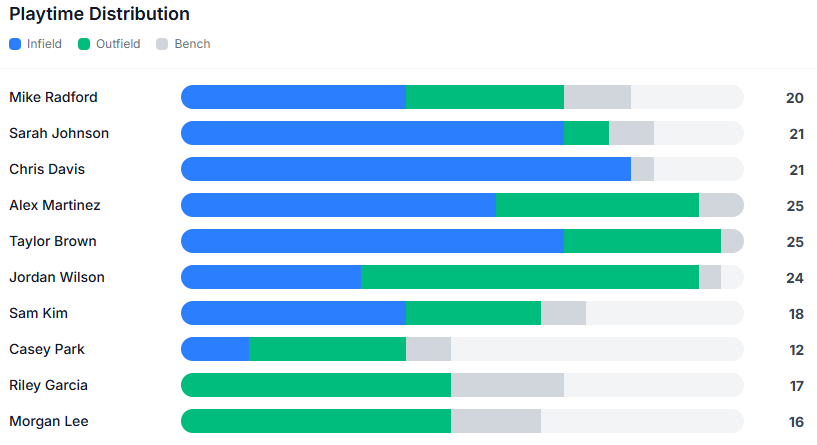
All nice ideas and cool to have but these along with other insights and reports are parked behind a door labeled “scorekeeping.”
No scorekeeping, no data. No data, no screens. I wasn’t just losing a few coaches who wanted pitch counts. I was losing the entire second half of the product I thought I was building.
So, yes. Another app inside my app.
“Build Me a Scorekeeping App for BenchBoard” Is Not a Prompt
Here is where I have to pause and say something to the growing choir of voices claiming software engineers are about to be obsolete.
Open a fresh chat with whichever LLM you like. Type the prompt:
> *Build me a scorekeeping app for BenchBoard.*
You will get code. Lots of it. It will compile. It will run. A demo will appear on your screen. You can tap a button and a “1” will increment somewhere. And that’s where the camera will stop.
Twitter will clip it. A YouTuber will make a 30 minute video from a 10 second clip and call it the end of the software engineering as we know it. Hell, pick almost any high skill profession that has a ton of logic gates to open through.
Now ship that to a youth coach in the middle of a real game and watch what happens. This is what the media does NOT show.
Because that prompt has no answer. There is no single prompt that produces a scorekeeping system. There is a tree of decisions, and every branch requires both knowledge of baseball and knowledge of how to build software, and those two things are almost never in the same person.
That is the actual job.
That’s what has to exist in someone’s head, and that’s what the AI cannot do on its own.
Let me show you what I mean. I’ll pull from a single file in my codebase — the domain model. This is one C# file. It literally defines the shapes of things that scorekeeping has to be aware of (database schema for all you seasoned devs out there). It’s basically where the stats go. How many strikes are thrown. Etc. Nothing fancy. No logic. Just the list of entities that must exist for the system to function.
Quick normie translation. Entities are the boxes on your scorecard. Every little pre-printed rectangle with a label above it. “Pitcher.” “Batter.” “Inning.” “Out.” If your scorecard doesn’t have a box for a thing, that thing cannot exist in your world. You can’t write “guest player” on a scorecard that has no row for guest players — you’ll stuff them into the roster row, and now your roster is wrong for the rest of the season.
Entities are those boxes. A data model is just a scorecard for the computer. And if the scorecard is missing a box, the computer cannot remember what you didn’t give it a place to write down.
Here is an abbreviated tour:
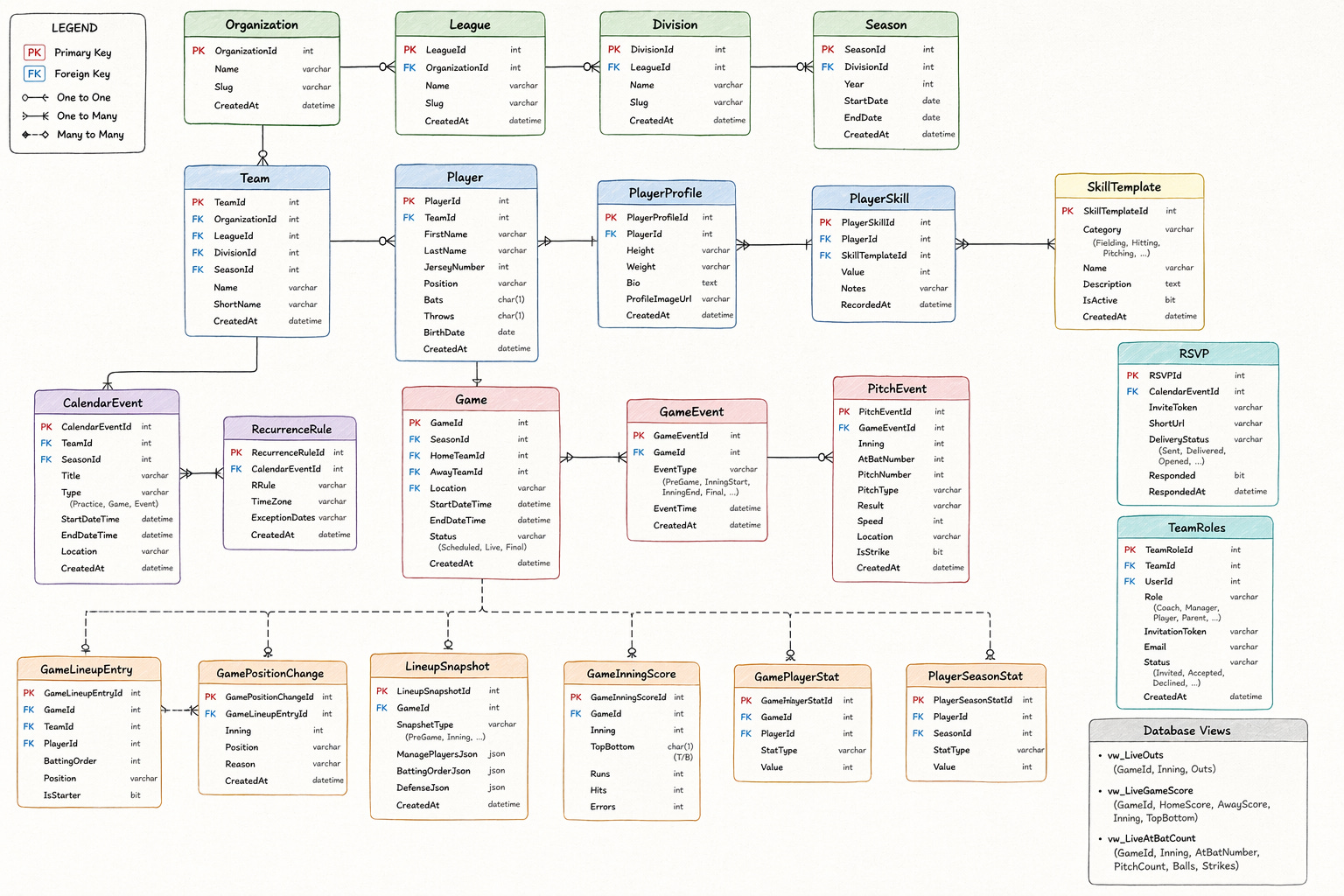
Yes. I know. To a normal person, this is a lot to take in. But to a seasoned developer this is nothing. But that’s one file. I have four others. Roughly 1,300 lines of model code in total, before a single line of business logic, frontend code, database migration, or SignalR wiring gets written. And none of those shapes were invented because a textbook told me to. Every single one exists because something in the real game forced it. In other words, a human did that. No AI decided that’s how the tables would look.
Take a look at one table (or entity) and see how deep it goes.
GamePlayerStat. This is the per-game stats row. How many fields does it have? A little over fifty. AB, H, R, RBI, BB, SO, HBP, SF, TB, Singles, Doubles, Triples, HR, PA, SH, IBB, SB, CS, GIDP, XBH, PickedOff, IP, ER, HRAllowed, BBAllowed, SOThrown, Pitches, Strikes, Balls, BF, H_Allowed, R_Allowed, WP, HB, BK, W, L, SV, BS, HLD, QS, GS, CG, SHO, PO, A, E, DRS, InningsByPosition, PositionInningsJson, DP, TP, PB, SB_Allowed, CS_Caught, RF…* and I'm stopping because the list goes on.
Some of you who know baseball (or even softball) may know half of what some of these are — and we haven’t even begun to talk about how to manage users.
For the non-coders: picture the back of a baseball card.
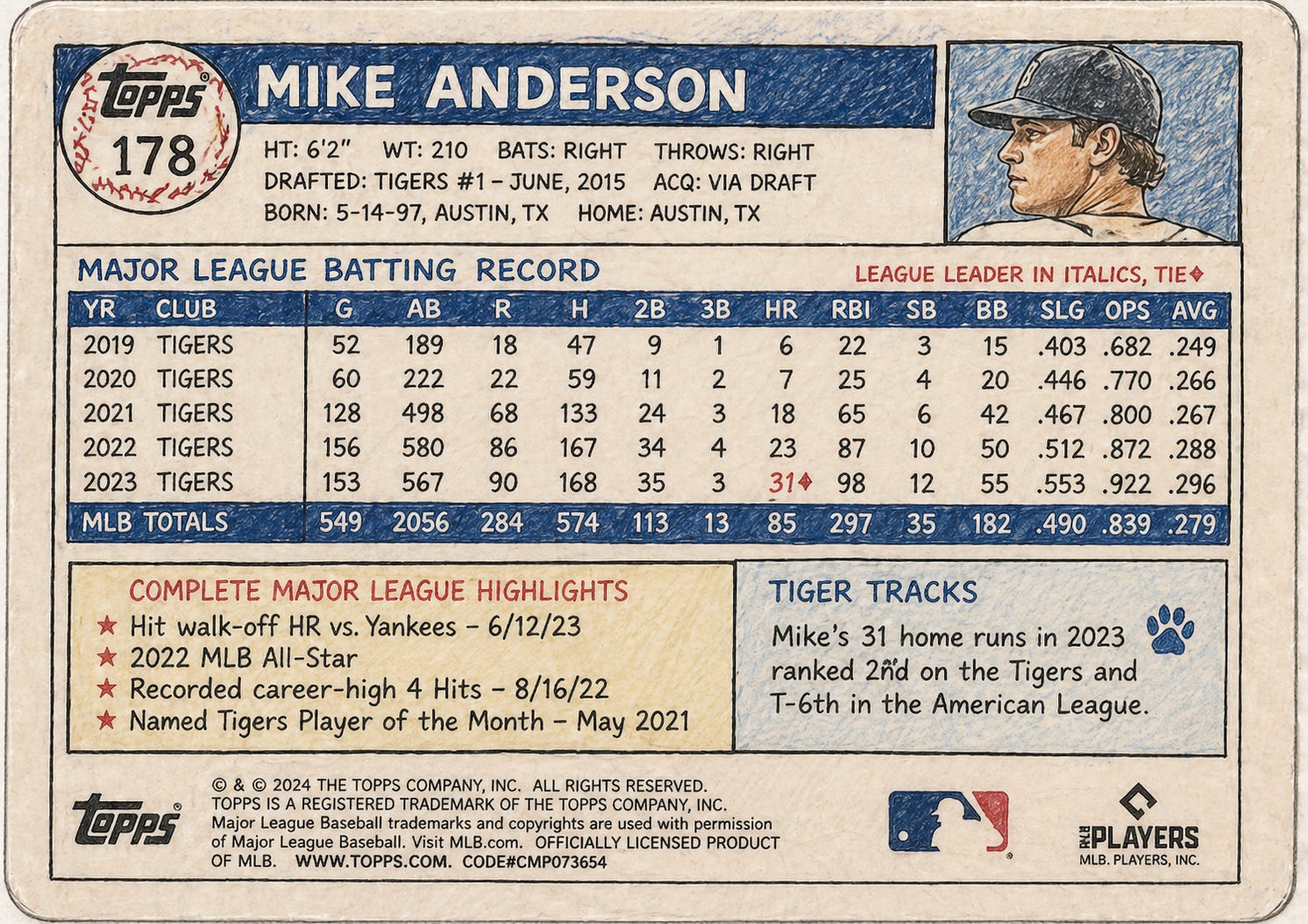
Every tiny number crammed in microscopic font across the bottom. Batting average, on-base percentage, stolen bases, caught stealing, sacrifice flies. Now imagine a card like that for every kid, for every game, for every season, for every team he (or she) is in. That is what this row is. Fifty little boxes the app has to remember to fill in, or remember not to fill in, every single time somebody swings a bat or throws a pitch.
Now tell me where in the "build me a scorekeeping app" prompt the AI decides which of those fifty fields to include, which to skip for youth vs. college, which ones are derived from other fields, which ones are entered directly by the scorekeeper, and which ones only exist because Range Factor is a thing in advanced baseball analytics but not in a rec league.
It doesn't.
It can't.
Someone has to sit at a table with a coach wearing a developer hat and decide. This is one of just a million examples where the non-developer has to sit down and decide where things go, how things should operate, how things should display. In fact, I’ve seen some examples online that are just simply broken. And we’re not even talking about how we deploy this damn thing or what devices it should be on, or even how it should look on each of those devices.
Then there’s the actual architecture of the system itself.
The SignalR hub and its scoping rules. The master orchestrator pipeline that hydrates game state from the event log on reconnect — basically when devices are disconnected, devices wait until it’s online THEN sends the updates to the internet fot safekeeping. The thirty-plus database migrations to get here. The SolidJS frontend stores, their persistence, their cross-environment token isolation. The SMS pipeline with its invite tokens and delivery status — which is basically texting a phone and letting you know it made it via “Read”. The admin dashboard. The Stripe linkage to get customers to pay for stuff like a subscription. The MFA flows for both users and admins to keep things secure. The incident tracking. The feature flag system. The SkillTemplate catalog. The Settings table keyed by entity type. The list goes on.
All of that was in my head, on my whiteboard, in my notes, or in someone’s war story from a real game. None of it came from a single prompt.
None of it could.
And that’s just a taste of some of the backend stuff.
Why AI’s Suck Without Humans (which maybe my next headline)
This is the part where I not only still had to teach it baseball/softball but how to build things the right way.

Why This Takes Both
There is a loud narrative right now that software engineers are being automated out of a job. That the LLM is the new senior engineer and the rest of us are just typing slower versions of what it already knows. I have been doing this for thirty plus years. I have not been more convinced than I am right now that the opposite is true.
Here is how this actually breaks down.
The AI is excellent at the inside of a file. Give it a clear shape, a clear responsibility, and it will fill in methods, handle null checks, write test scaffolding, and clean up types faster than I can. It is a phenomenal accelerator for the parts of software engineering that are already understood. Part 2 of this series has more examples of that working for me.
But the AI is a tourist at the outside of the file. It does not know which entities should exist. It does not know whether a concept deserves a table, a JSON blob inside a table, an enum, a view, or a nothing. It does not know whether two things that look similar in a schema diagram are actually the same thing or are about to diverge violently in six months. It does not know what a coach will actually look at on game day, which means it cannot tell you what data has to be ready for that screen.
And it does not know what is missing. That’s the one that gets you. The AI will happily build what you ask for. It will not tell you that you forgot about walk-ups, fractional innings, pitch clock violations, dropped third strikes, passed balls, guest players with duplicate jersey numbers, or the difference between an opponent team and a registered team. Those gaps don’t show up until a real coach is standing in a real dugout and something happens that your schema can’t hold.
This is where knowing the lay of the land as a coach and a software engineer gives you a unique perspective. You understand the scope of the problem, its impact, and what it means to have a system that actually works. It’s like being the head chef in a kitchen. You know the equipment. You know the recipe. You know what your customers want and what tastes good to them. Only you can take your squad, agentic or not, to the right place.
The AI is the line cook. A very fast, very tireless, never-complains line cook. It is not the head chef.
Software Engineers Aren't Obsolete. They're the Job.
I’ll leave you with this.
The part of my build that the AI accelerated the most — the methods, the controllers, the scaffolding, the boilerplate, the CSS — is the part that was already solved by somebody in the training data. I got a real speedup there. It was worth every token.
The part that the AI could not do, would not do, did not even know needed to be done, is the part that separates a demo from a system of record. The shape of the data. The choice of what to cache and what to derive. The list of domain rules you will be punished for violating. The judgment about which textbook answer is wrong in this specific case. The willingness to throw out the first version because you can smell the drift coming from three months down the road.
That is software engineering. Not typing. Not syntax. Not reading a doc and producing a function. It is the accumulated muscle of having been wrong before, in ways you remember, about systems that mattered. And then, on top of all of that, knowing the domain well enough to build for it.
One of the reasons I’m writing this series is that I’m watching a narrative build in public — in podcasts, on X, in press releases — that says this profession is ending.
I’m telling you, from inside a build, that it is the opposite. The AI raised the ceiling on what one person can ship. It did not remove the need for someone to know what to ship. The gap between “working demo” and “thing a coach will trust with their kid’s pitch count” is exactly the gap between someone who has never been in a dugout and someone who has.
Scorekeeping wasn’t the hard part because it was complex code. It was the hard part because every choice had a rule behind it that lived in someone’s head, and that someone had to sit in the same chair as the developer.
I know that’s overwhelming for a single person. It is. It has been.
But it is also why this is still a job.
One Last Thing
Near the beginning of the current AI wave, one of the smartest and most influential computer scientists alive — one of the actual fathers of modern deep learning, a Turing Award winner, somebody whose ideas the entire current boom is built on top of — stood in front of a conference and said this:

“I think that if you work as a radiologist you’re like the coyote that’s already over the edge of the cliff but hasn’t yet looked down... People should stop training radiologists now. It’s just completely obvious that within five years, deep learning is going to do better than radiologists.”
That was Geoffrey Hinton. In 2016.
Five years came and went. Ten is almost up. Radiologists are still radiologists. There are more of them today than there were the day he said it, and they are working alongside AI tools that make them faster and better, not unemployed. The prediction was confident. It was mathematically reasoned. It was delivered by somebody with more authority than anyone writing the same sentence today about software engineers.
And it was wrong.
So when you see the same confident tone, the same “ten years” timeline, the same “the profession is ending” chorus pointed at my line of work — I want you to scroll back up. Read about fractional innings. Read about the three-ring binder. Read about the empty chair and the photograph that can’t update its own hair. Read about the 9-pane window drawn over home plate, and the mailbox full of envelopes that all look the same until you know who sent them.
Then ask yourself whether a prompt is going to figure any of that out.
I’ll see you in Part 4. Thanks for reading.
Coming Up in Part 4
Part 3 was the shape of the problem. Part 4 is what happens when you try to make the shape actually run in a real game on a real field with a real network.
I’ll get into the implementation stories that followed. The cache-vs-view decision that kept the ball-and-strike count from lying to a dugout. The guest player with the duplicate jersey number who would have silently corrupted the stats table if I’d matched the textbook way. The real-time communication pipes that let a scorekeeper’s tap become a scoreboard update for a parent in the parking lot. The race condition I hunted down where End Inning kept putting phantom runners on second base. The decision to stop broadcasting by team and start broadcasting by game — which the AI called “architecturally correct” once I handed it the answer, but would not have volunteered. And the master orchestrator pipeline I had to design when the AI’s first fix for a different bug kept re-introducing the bug I’d just fixed.
Part 5 brings it home: what I've learned about shipping with AI, what I've stopped doing, what I've started doing, and the single question I now ask before I accept any prompt's output.